近期,360私有云容器服务团队和人工智能研究院团队展开配合,在云端提升机器学习的效能方面进行了深入的研究和实践,为业务提供了“人脸检测”、“花屏检测”、“色情检测”、“宠物检测”、“图片风格化”、“文字识别”、“智能裁图”等多种深度学习服务。
下面主要介绍下此次实践的两方面技术:“TensorFlow Serving”和“微服务网关与容器服务”。
TensorFlow Serving
简介
TensorFlow Serving是2016 年 2 月发布并开源的一种用于机器学习模型的灵活、高性能的 serving 平台。它使得部署新的模型变得更加容易,同时保持了相同的服务器架构和API。而且,它还提供了TensorFlow模型的开箱即用的集成,但是可以很容易地扩展为其他类型的模型和数据。TensorFlow Serving 就是一个专为生产环境设计的。标准化了模型的定义及模型发布的流程(模型领域的CI/CD)。
机器/深度学习服务在模型发布方面有很多需求:
- 支持模型版本化
- 多种模型(通过 A/B 测试进行的实验)并行提供服务
- 确保并行模型在硬件加速器(GPU 和 TPU)上实现高吞吐量和低延迟时间
- 模型的动态加载
- 模型的对外接口支持(RPC、restful 等)
- 批量任务的支持
工作机制
TensorFlow Serving 将每个模型视为可服务对象。它定期扫描本地文件系统,根据文件系统的状态和模型版本控制策略来加载和卸载模型。这使得可以在TensorFlow Serving继续运行的情况下,通过将导出的模型复制到指定的文件路径,而轻松地热部署经过训练的模型。
其工作流程和原理可参考下面这张图: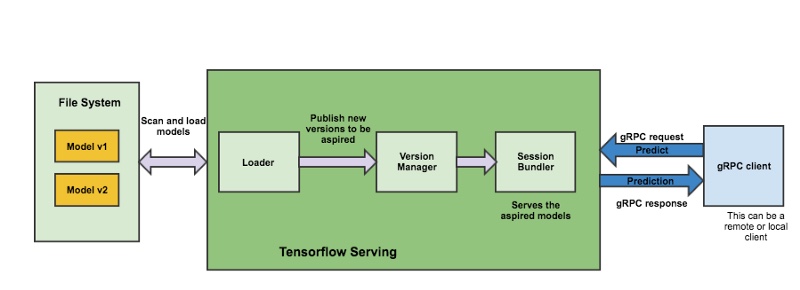
从 1.8.0 版本开始提供了 restful api 的支持,上图中只给出了 gRPC 的接口方式。
对于gRPC api server 和 restful api server 都是通过 C++ 实现。主要功能就是以接口的形式对外暴露 模型的能力。 restful api 的实现:https://github.com/tensorflow/serving/blob/master/tensorflow_serving/model_servers/http_server.cc
除了提供基础的rpc server的功能外,亮点在于一下几个feature:
- 标准化的模型格式
- 多模型管理:从一个模型到多个并发的服务模型,呈现出几个性能障碍。通过
- 在隔离的线程池中加载多个模型,以避免在其他模型中出现延迟峰值;
- 在服务器启动时,加速所有模型的初始加载;
- 多模型批处理到多路复用硬件加速器(GPU/TPU)。
- 多版本管理:
- 可以同时load多个版本的model,并且客户端可以访问指定的版本。
- 模型热加载:新版本的model发布后,自动加载新版本。
- 版本管理的policy是可以定制的。默认主要实现的有两种:Availability Preserving Policy和Resource Preserving Policy。
- 支持从多种存储上加载模型:
- 默认支持本地存储、hdfs存储、S3存储(不过S3需要在编译时打开开关)。
- 可以扩展支持更多种类的存储(可以通过插件形式提供对其它存储类型的支持)。
- client端访问的批处理功能:同样,这个功能也是可以自定义policy。
- 灵活的扩展性。可以实现自己的plugin对其实现定制和功能扩充。
TensorFlow Serving设计的非常灵活,扩展性也非常好,可以自定义插件来添加新功能的支持。 例如,你可以添加一个数据源插件监听云存储来替代本地存储方式,或者你还可以添加新的版本管理策略插件来控制多版本切换的策略,甚至还可以通过插件的方式添加对非TensorFlow 模型的支持。详情见 和 。
模型管理策略
当有新版本的model添加时,AspiredVersionsManager 会加载新版本的模型,并且默认行为是卸载掉旧版本模型。
当前是可以配置的,目前支持3中类型:- 加载所有版本模型
- 加载最近的几个版本模型
加载执行版本的模型
模型管理和加载策略通过配置文件控制,配置文件格式:model_config_list: { config: { name: "mnist", base_path: "/tmp/monitored/_model",mnist model_platform: "tensorflow", model_version_policy: { all: {} } }, config: { name: "inception", base_path: "/tmp/monitored/inception_model", model_platform: "tensorflow", model_version_policy: { latest: { num_versions: 2 } } }, config: { name: "mxnet", base_path: "/tmp/monitored/mxnet_model", model_platform: "tensorflow", model_version_policy: { specific: { versions: 1 } } }}
模型存储支持
- 默认是本地存储。
现在已经支持从HDFS加载模型:
--model_base_path=hdfs://xx.xx.xx.xx:zz/data/serving_model"]
S3 也增加了支持,但是需要自己在编译tensorflow_model_server时添加支持,详见链接:
https://github.com/tensorflow/serving/issues/669 https://github.com/tensorflow/serving/issues/615
API 实现机制
从 1.8.0 开始提供了两种 API: gRPC 和 Restful,他们都是通过C++实现的。它们的职责很简单也很清晰就是将 ServerCore 的功能和能力暴露出来对外使用。只是协议不通,核心的逻辑是复用的。
接口是否支持异步?目前支持 batching 的处理。Batching 设计详见:https://github.com/tensorflow/serving/blob/master/tensorflow_serving/batching/README.md模型训练和导出
模型训练过程就是Tensorflow模型训练那一套,现在主要着重说一下如何把训练好的模型导出成TFServing的标准格式。TFServing中模型是标准化的,模型的导出需要按照相应的规范导出才能在TFServing中被识别和加载。在官方提供的例子中,例如mnist_saved_model.py所示,加载模型之后,需要构建signature_def_map,然后以这种方式导出成TFserving可以使用的格式。
需要注意区分prediction,classification和regression的不同map的定义,在之后的Restful API的调用中,需要和定义的signature_name及key保持一致。 构建完成之后,文件目录为这样:assets/assets.extra/variables/ variables.data-?????-of-????? variables.indexsaved_model.pb
模型的部署
有了模型后,就需要通过 TensorFlow Serving 来加载模型并提供服务。在这里我们是以容器的方式来运行 TensorFlow Serving,官方有已经构建好的。
先来看看 tensorflow_model_server 的使用:/usr/local/bin/tensorflow_model_server --helpusage: tensorflow_model_serverFlags: --port=8500 int32 Port to listen on for gRPC API --rest_api_port=0 int32 Port to listen on for HTTP/REST API. If set to zero HTTP/REST API will not be exported. This port must be different than the one specified in --port. --rest_api_num_threads=128 int32 Number of threads for HTTP/REST API processing. If not set, will be auto set based on number of CPUs. --rest_api_timeout_in_ms=30000 int32 Timeout for HTTP/REST API calls. --enable_batching=false bool enable batching --batching_parameters_file="" string If non-empty, read an ascii BatchingParameters protobuf from the supplied file name and use the contained values instead of the defaults. --model_config_file="" string If non-empty, read an ascii ModelServerConfig protobuf from the supplied file name, and serve the models in that file. This config file can be used to specify multiple models to serve and other advanced parameters including non-default version policy. (If used, --model_name, --model_base_path are ignored.) --model_name="default" string name of model (ignored if --model_config_file flag is set --model_base_path="" string path to export (ignored if --model_config_file flag is set, otherwise required) --file_system_poll_wait_seconds=1 int32 interval in seconds between each poll of the file system for new model version --flush_filesystem_caches=true bool If true (the default), filesystem caches will be flushed after the initial load of all servables, and after each subsequent individual servable reload (if the number of load threads is 1). This reduces memory consumption of the model server, at the potential cost of cache misses if model files are accessed after servables are loaded. --tensorflow_session_parallelism=0 int64 Number of threads to use for running a Tensorflow session. Auto-configured by default.Note that this option is ignored if --platform_config_file is non-empty. --platform_config_file="" string If non-empty, read an ascii PlatformConfigMap protobuf from the supplied file name, and use that platform config instead of the Tensorflow platform. (If used, --enable_batching is ignored.) --per_process_gpu_memory_fraction=0.000000 float Fraction that each process occupies of the GPU memory space the value is between 0.0 and 1.0 (with 0.0 as the default) If 1.0, the server will allocate all the memory when the server starts, If 0.0, Tensorflow will automatically select a value. --saved_model_tags="serve" string Comma-separated set of tags corresponding to the meta graph def to load from SavedModel. --grpc_channel_arguments="" string A comma separated list of arguments to be passed to the grpc server. (e.g. grpc.max_connection_age_ms=2000)
镜像
注意镜像有 CPU 版本和 GPU 版本,根据需要来选择。同时,如果官方给的镜像满足不了需求,还可以自己使用官方的Dockerfile来构建。不过默认的功能已经能满足大部分的需求,很少去对 TensorFlow Serving 本身添加功能,所以官方构建好的镜像已经够用。
官方镜像的坑
使用官方默认的镜像在加载模型时提示找不到可用的GPU设备,问题出在环境变量 LD_LIBRARY_PATH 的设置上。 默认官方镜像为: LD_LIBRARY_PATH=/usr/local/cuda/lib64/stubs:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/nvidia/lib:/usr/local/nvidia/lib64 需要修改为: LD_LIBRARY_PATH=/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/local/cuda/lib64/stubs:/usr/local/cuda/extras/CUPTI/lib64 默认搜索路径是顺序搜索,搜索到后就不再往后匹配。使用/usr/local/cuda/lib64/stubs:/usr/local/cuda/extras/CUPTI/lib64中的libcuda.so库没办法驱动GPU设备。
模型存储及策略配置
模型的存储位置及策略可以通过 --model_config_file 参数指定
model_version_policy目前支持三种选项:- all: {} 表示加载所有发现的model;
- latest: { num_versions: n } 表示只加载最新的那n个model,也是默认选项;
- specific: { versions: m } 表示只加载指定versions的model,通常用来测试; model_config_file 配置文件样例:
model_config_list: { config: { name: "mnist", base_path: "/tmp/monitored/_model",mnist model_platform: "tensorflow", model_version_policy: { all: {} } }, config: { name: "inception", base_path: "/tmp/monitored/inception_model", model_platform: "tensorflow", model_version_policy: { latest: { num_versions: 2 } } }, config: { name: "mxnet", base_path: "/tmp/monitored/mxnet_model", model_platform: "tensorflow", model_version_policy: { specific: { versions: 1 } } }} 这里不多解释,很容易看明白。
启动服务
这里以在本地容器方式启动。
模型文件存放在 /data/ 目录下,内容如下-rw-r--r-- 1 root root 235 Jul 10 17:00 model-config.jsondrwxr-xr-x 1 root root 15 Jul 10 11:15 models model-config.json 是要使用的 model-config-file。models 目录下都是一些官方的模型例子。 [root /mnt/zzzc]# ll models/total 12drwxr-xr-x 1 root root 1 Jul 6 12:15 bad_half_plus_two-rw-r--r-- 1 root root 25 Jul 6 12:15 bad_model_config.txt-rw-r--r-- 1 root root 135 Jul 6 12:15 batching_config.txt-rw-r--r-- 1 root root 2205 Jul 6 12:15 BUILD-rw-r--r-- 1 root root 1988 Jul 6 12:15 export_bad_half_plus_two.py-rw-r--r-- 1 root root 3831 Jul 6 12:15 export_counter.py-rw-r--r-- 1 root root 1863 Jul 6 12:15 export_half_plus_two.py-rw-r--r-- 1 root root 268 Jul 6 12:15 good_model_config.txtdrwxr-xr-x 1 root root 1 Jul 6 12:15 half_plus_twodrwxr-xr-x 1 root root 2 Jul 6 12:15 half_plus_two_2_versionsdrwxr-xr-x 1 root root 1 Jul 10 11:22 huapingdrwxr-xr-x 1 root root 1 Jul 9 18:31 porndrwxr-xr-x 1 root root 1 Jul 6 12:15 saved_model_counterdrwxr-xr-x 1 root root 1 Jul 6 12:15 saved_model_half_plus_threedrwxr-xr-x 1 root root 2 Jul 6 12:15 saved_model_half_plus_two_2_versions
model-config.json 内容如下(这里我以json文件后缀命名,这个都行):
# cat model-config.jsonmodel_config_list: { config: { name: "half_plus_three", base_path: "/data/models/saved_model_half_plus_two_2_versions", model_platform: "tensorflow", model_version_policy: { all: {} } }} saved_model_half_plus_two_2_versions 包含了 2 个版本(123和124)模型,这里也是演示的加载多个版本模型的场景。
[root@dlgpu12 /mnt/zzzc/models/saved_model_half_plus_two_2_versions]# tree.├── 00000123│ ├── assets│ │ └── foo.txt│ ├── saved_model.pb│ └── variables│ ├── variables.data-00000-of-00001│ └── variables.index└── 00000124 ├── assets │ └── foo.txt ├── saved_model.pb └── variables ├── variables.data-00000-of-00001 └── variables.index
我们将这个目录挂载到容器内部(线上可以通过 CephFs 数据卷的方式使用)
nvidia-docker run -it --rm --entrypoint="/usr/local/bin/tensorflow_model_server" \ -v /data:/data \ tensorflow-serving:1.8.0-devel-gpu \ --model_config_file=/data/model-config.json
这样,我们就通过TensorFlow Serving把模型给跑起来了。
这里只是指定了 model_config_file,其它的配置可以根据实际需要使用。Client 端的接入
Client端的接入有两种方式: gRPC 和 Restful。
具体使用可详见: https://www.tensorflow.org/serving/serving_inception https://www.tensorflow.org/serving/api_rest模型的动态更新和发布
模型的动态更新和发布是通过 model-config-file配置来实现的,默认将新版本模型放到指定的目录下即可,系统会自动扫描并加载新的模型。
微服务网关(kong)与容器服务
背景
公司的一些团队想将他们的服务已容器的方式进行快速部署交付。对于一些简单的单体应用,直接通过公司的负载均衡就可以了。但是如果想要将多个小的应用(如:人脸检测,图片检测等)最终归类为一个大的应用来对外提供服务的话,就需要网关来做这件事情。基于该背景,我们调研了当下比较流行的微服务网关(Kong)。
什么是微服务架构
微服务是一种构建软件的架构和方法。在微服务中将以前的单体应用被拆分成多个小的组件,并彼此独立。不同于将所有组件内置于一个架构中的传统单体式应用的构建方法,在微服务架构中,所有的部分都是相互独立的(可以使用不同的语言,不同团队来开发不同的服务模块)。通过合作来完成相同的任务。其中的每一个组件或流程都是微服务。总结微服务的特点就是:更小, 更快, 更强。
可能通过上面对微服务的描述还是不是特别的直观,将传统的单体应用架构和微服务架构进行下比较,就比较直观了。
1.单体应用架构
最早对于web程序的开发(比如JAVA),通常将整个程序打包到一个WAR文件中,然后直接部署到服务器即可。
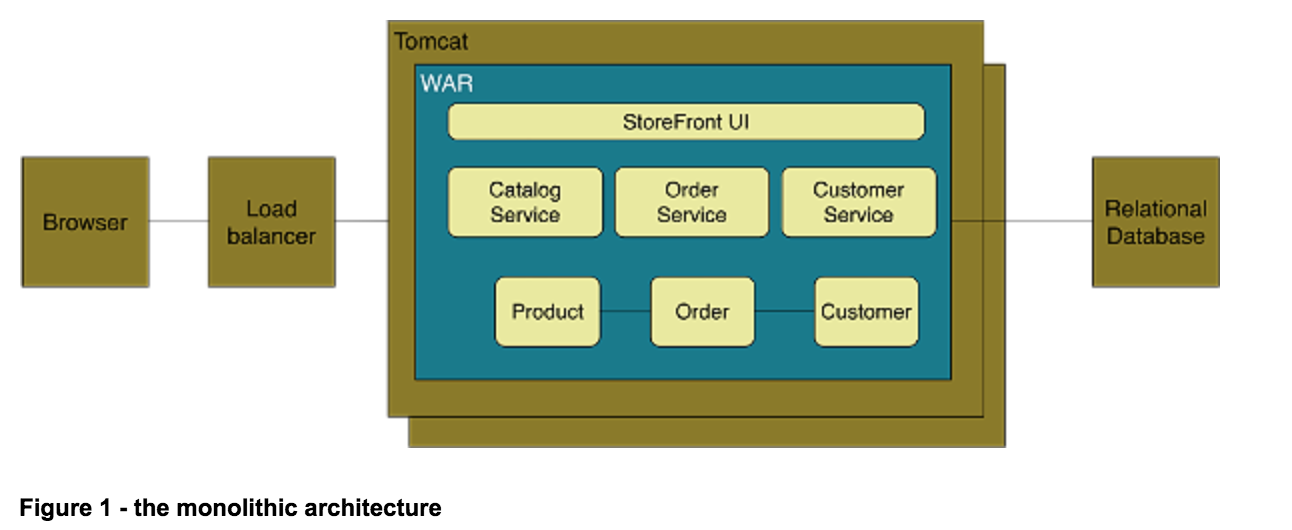
单体应用架构易于测试和部署,但是在服务的可伸缩性,可靠性, 系统迭代, 跨语言程序, 团队协作等方便没有微服务方便。
2.微服务架构
为了解决单体应用架构的这些诸多弊端(不是说单体应用架构不好,需要根据不同的业务场景选择不同的服务架构)。可以将单体应用架构拆分成多个独立的小的组件。
这样就可以每个团队使用自己的技术栈来实现自己的组件,并在系统迭代的时候独立的进行迭代而不影响整个应用的整体使用。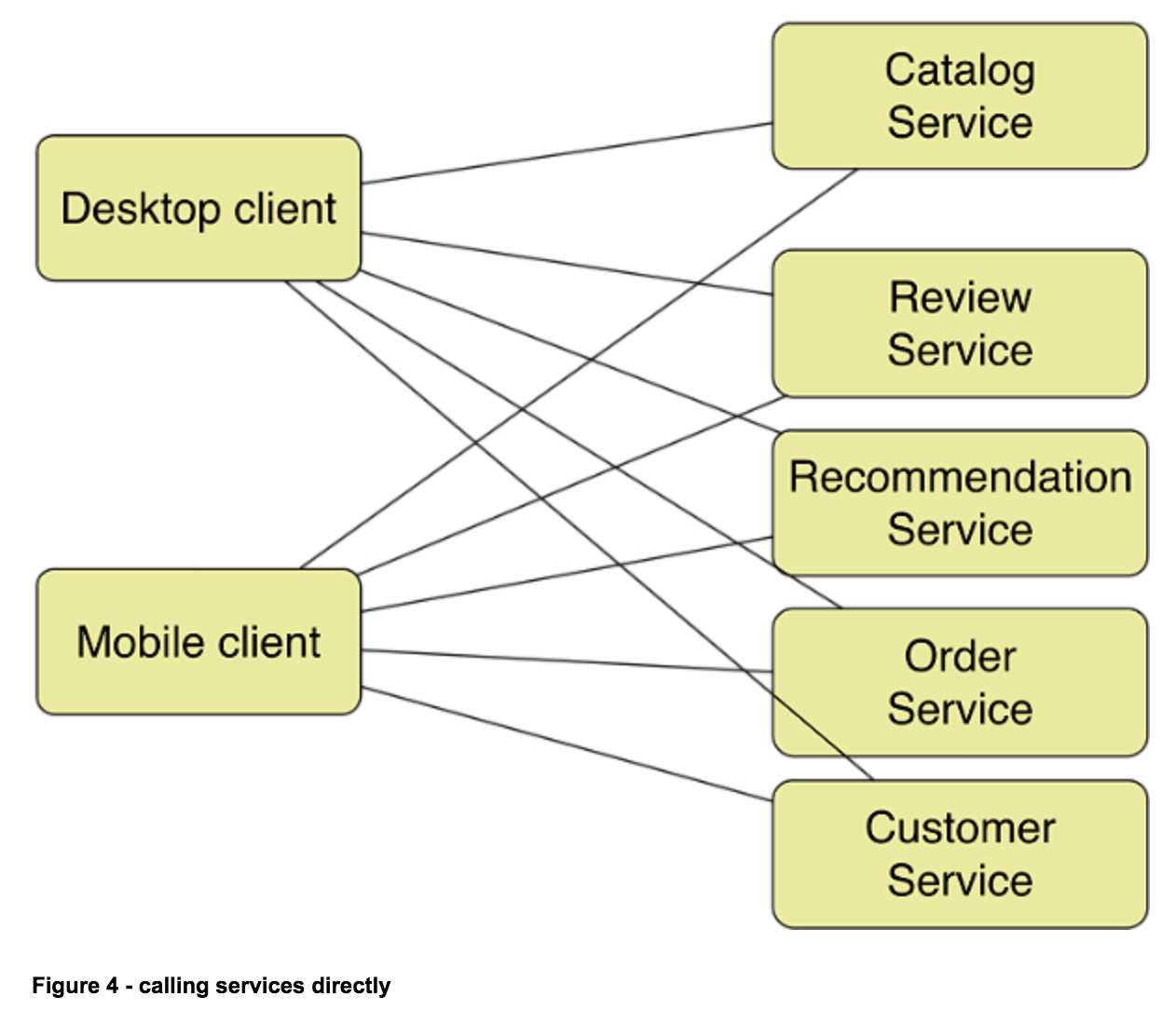
为什么需要微服务网关
首先介绍下什么是API网关,API网关可以提供一个单独且统一的API入口用于访问内部一个或多个API服务。API网关常会提供负载均衡,访问频率限制,认证授权,监控,缓存等功能。
通过API网关,可以将内部服务对外部用户隐藏,而暴露给外部用户真实需要的API,并可以对外部访问进行访问频率的限制同时还可以对外部的用户设置认证授权。来保证应用整体的稳定及安全等等。而网关内部的服务则可以根据自己的需求通过相关的协议(REST API, GRPC)进行通信。
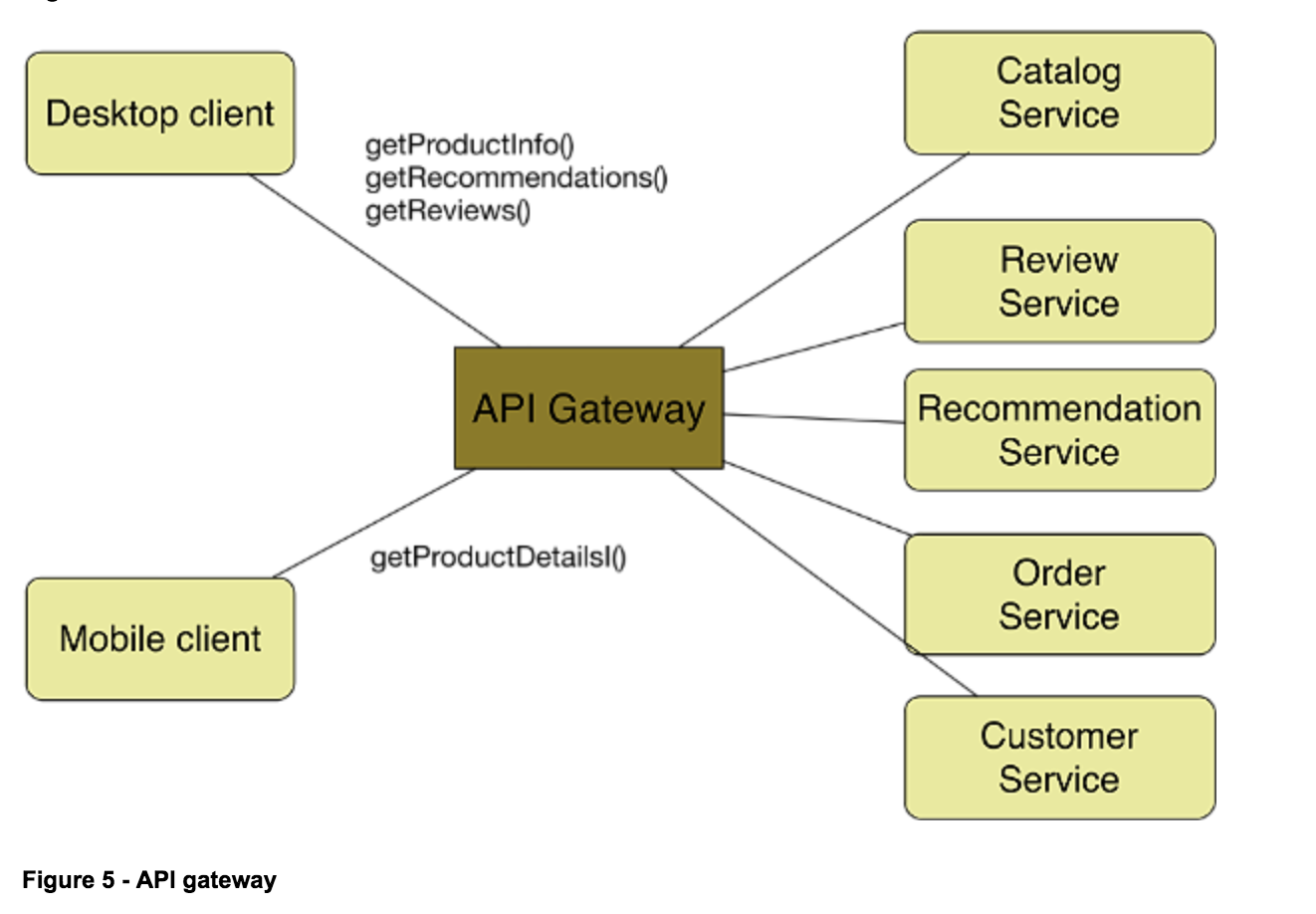
微服务网关(kong)介绍
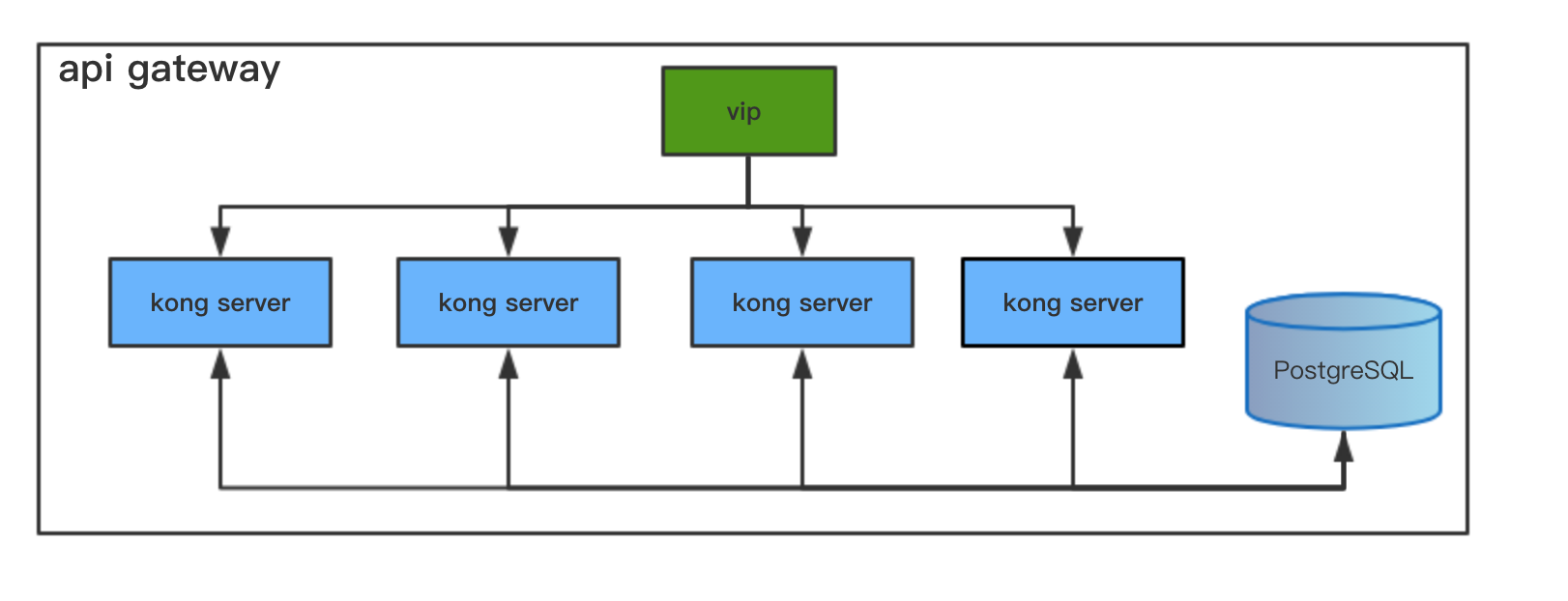
kong是一款基于nginx_lua模块写的高可用,易扩展的API网关。由于kong是基于nginx的,所以可以水平的扩展多个kong服务实例,通过前置的负载均衡配置把请求均匀地分到各个server,来应对大批量的网络请求。
kong网关组成:
- Kong server: 基于nginx的服务器,接收外部的api请求。
- PostgreSQL: 用来存储操作的数据。
并且kong采用插件机制进行功能的定制,插件集在API请求响应循环的生命周期中被执行。插件使用lua编写。
部署kong服务参考官方文档:
使用kong服务参考官方文档:
微服务网关(kong)如何与容器服务结合使用
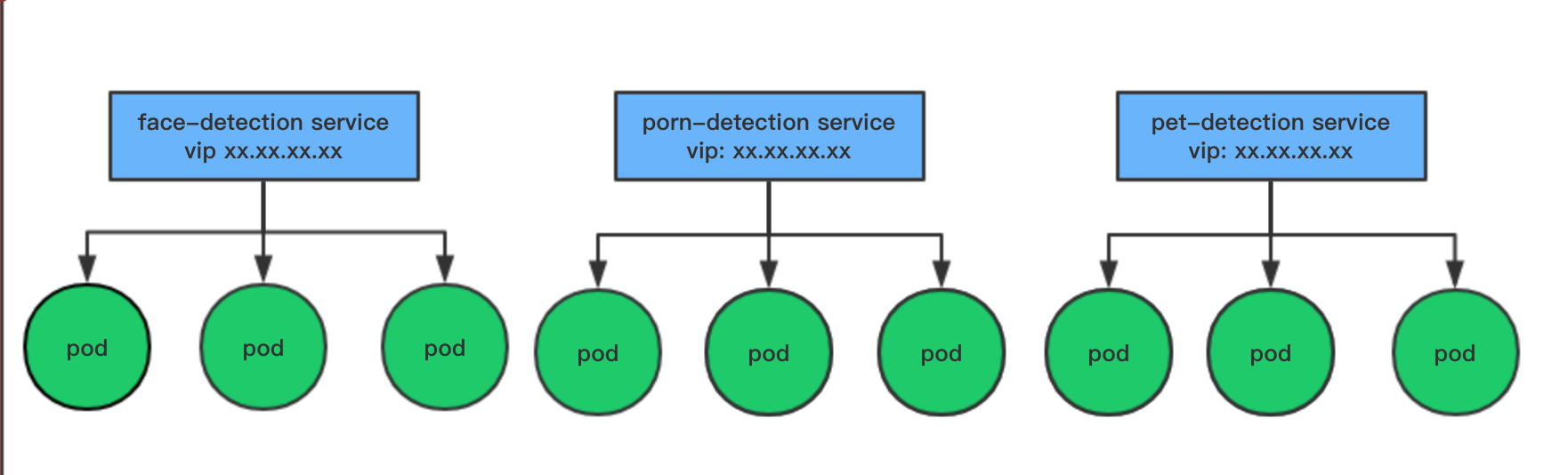
通过一个具体的例子来描述部署到容器上的服务是如何与微服务网关结合使用的。比如我们现在有人脸检测, 宠物检测, 鉴黄服务等将这个单独的服务组成一个完成的应用实体来对外提供多功能的服务。
1.首先在容器服务平台上部署我的三个服务实例(人脸检测,宠物检测,鉴黄服务)。并为这些服务实例申请vip。
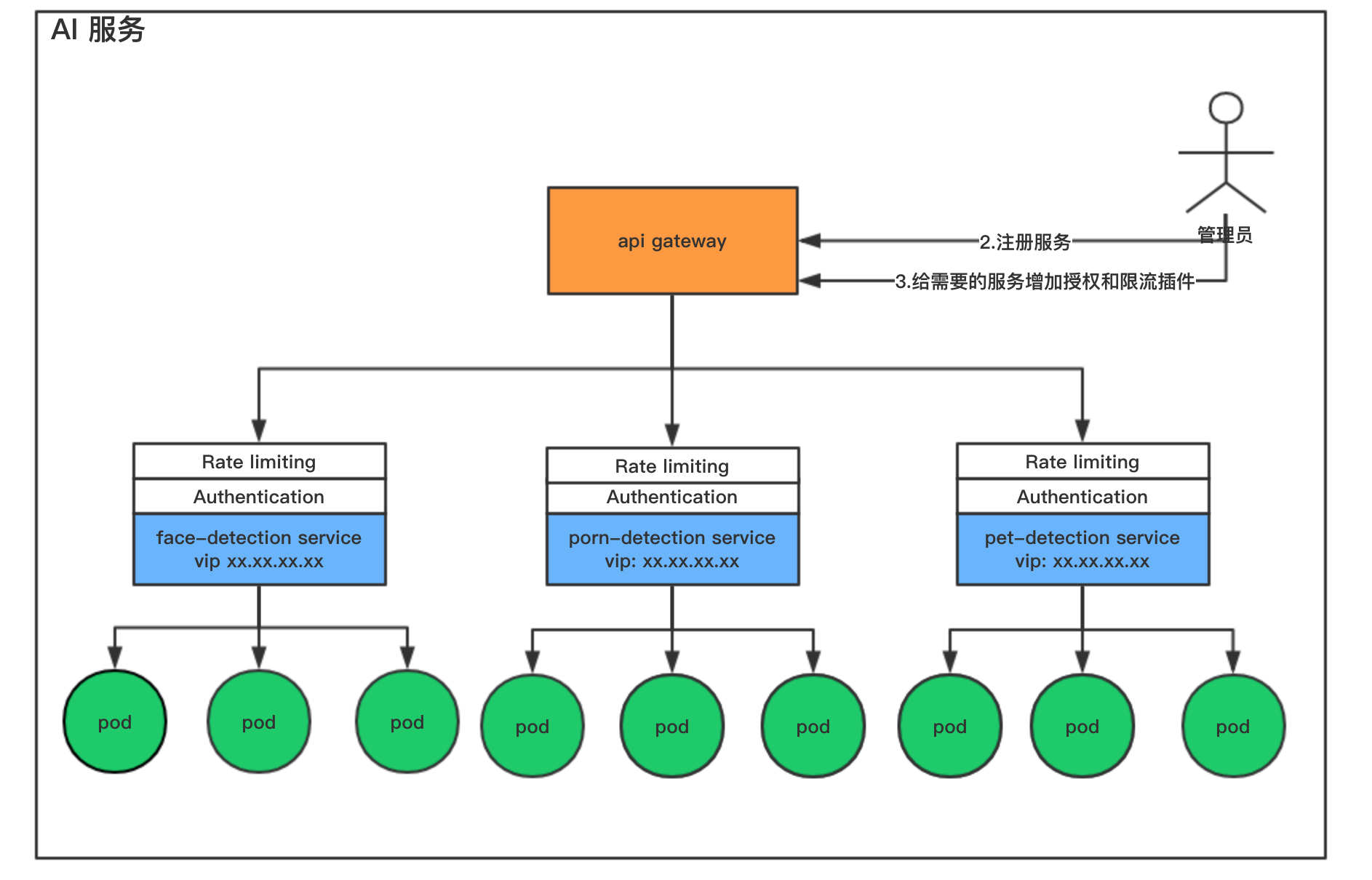
2.服务注册完成之后,管理端将这三个服务注册到微服务网关(kong),kong会将注册的信息持久化到PostgreSQL数据库。并可以根据不同的业务为各个服务已插件的形式注册认证授权,访问频率限制,CORS等插件。
3.当服务注册完成之后,用户端可以基于被授权的用户token去访问他们想要使用的服务。
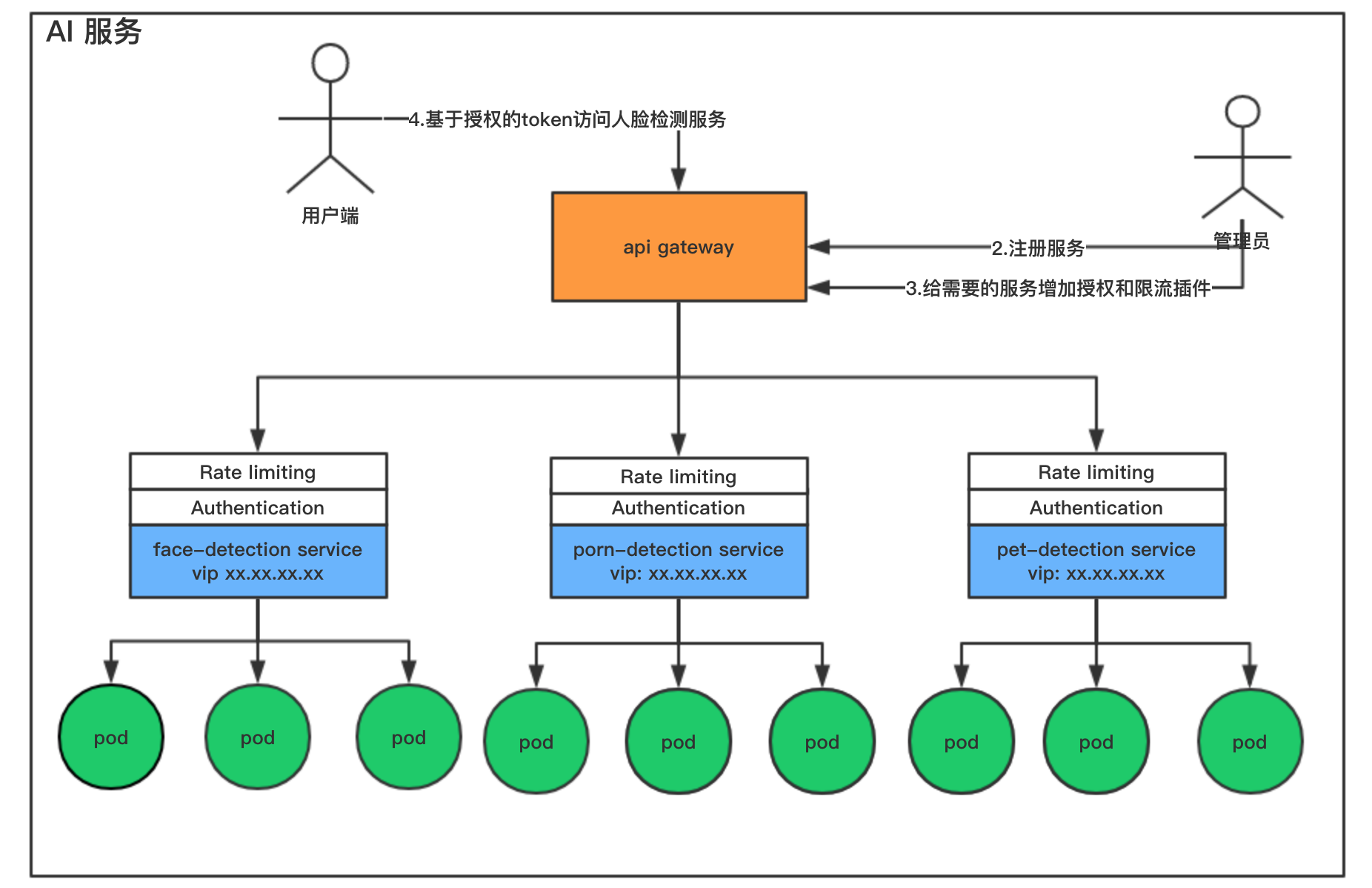
整体简单的流程就是这样,我只是简单地介绍了下整体的流程。但是每一个部分都需要用户自己去深入了解了:)